
CONNAISSEZ-VOUS SCREAMING FROG ?
Ok, une « grenouille hurlante », ça ne paraît pas très utile à première vue mais promis, vous allez gagner du temps, alors lisez cet article jusqu’au bout. Un crawler est un programme qui va parcourir votre site comme le fait Google et vous proposer un certain nombre d’informations plus ou moins intéressantes en fonction de vos besoins. Chez JETPULP, nous sommes adeptes de Screaming Frog, un crawler très connu des SEO et autres développeurs, administrateurs systèmes, etc. Cet outil assez bon marché (il existe une version gratuite limitée à 500 URLs) vous permet donc une fois configuré de parcourir votre site afin d’en extraire les données souhaitées. Par défaut, Screaming Frog vous remonte les éléments suivants (liste non exhaustive) pour le domaine (le site) que vous lui aurez demandé d’explorer :
- La réponse HTTP (200, 404, 301, 500 etc) de chaque page trouvée
- Le meta title et la meta description de chaque page
- La présence ou non de balise canonique
- Le contenu de la balise meta robots (ex: noindex,nofollow)
Ce qui nous intéresse dans un premier temps est de définir le type de données que vous pouvez extraire et qui ne se trouvent pas dans la liste de base. En voici deux exemples :
- Vous souhaitez savoir si les produits présents sur votre site sont en stock ou non.
- Vous souhaitez extraire vos descriptifs produit afin de les retravailler facilement. Vous pourriez également extraire les chapôs des catégories par exemple.
QUELLES DONNÉES EXTRAIRE ET COMMENT ?
Passons à présent à la pratique. Avant de commencer, voici les éléments dont vous aurez besoin :
- Un navigateur web (nous utiliserons Chrome)
- Screaming Frog
- Un peu de patience (ou beaucoup, en fonction de la taille de votre site)
Extraire votre volume de stock
Nous nous plaçons ici dans le cadre d’un site e-commerce dont la configuration est la suivante : lorsqu’un produit n’est plus en stock, la fiche produit est accessible, c’est à dire qu’elle répond en 200. Cela signifie qu’elle ne génère pas d’erreur et affiche correctement les informations du produit mais on ne peut pas le commander : soit le bouton d’ajout au panier a disparu, soit le contenu de ce dernier a été remplacé par un texte du type « Être prévenu lorsque le produit sera en stock ».
Dans ce deuxième cas, il va donc falloir demander à Screaming Frog d’extraire le contenu du bouton d’ajout au panier, et en fonction de ce contenu, nous saurons si le produit est en stock ou non. Pour cela, nous allons utiliser la fonction « Extraction » de l’outil en se basant sur le CSS Path. Celui-ci correspond aux éléments CSS qui permettent de repérer le contenu souhaité au cœur des pages du site. Faisons le test par exemple sur Easyparapharmacie, site e-commerce de produits de parapharmacie en ligne : tout d’abord, il faut détecter le bouton d’ajout au panier. Ensuite, il suffit de récupérer le CSS Path du bouton. Hum, ok mais comment fait-on ?
- Affichez depuis votre fiche produit la console de votre navigateur (F12 sous Chrome par exemple).
- Cliquez sur l’icône de sélection d’élément puis sur votre bouton d’ajout au panier : les éléments HTML/CSS contenant le bouton vont se mettre en surbrillance dans l’explorateur.
- Faites un clic droit sur l’élément puis faîtes Clic Droit > Copy > Copy selector.
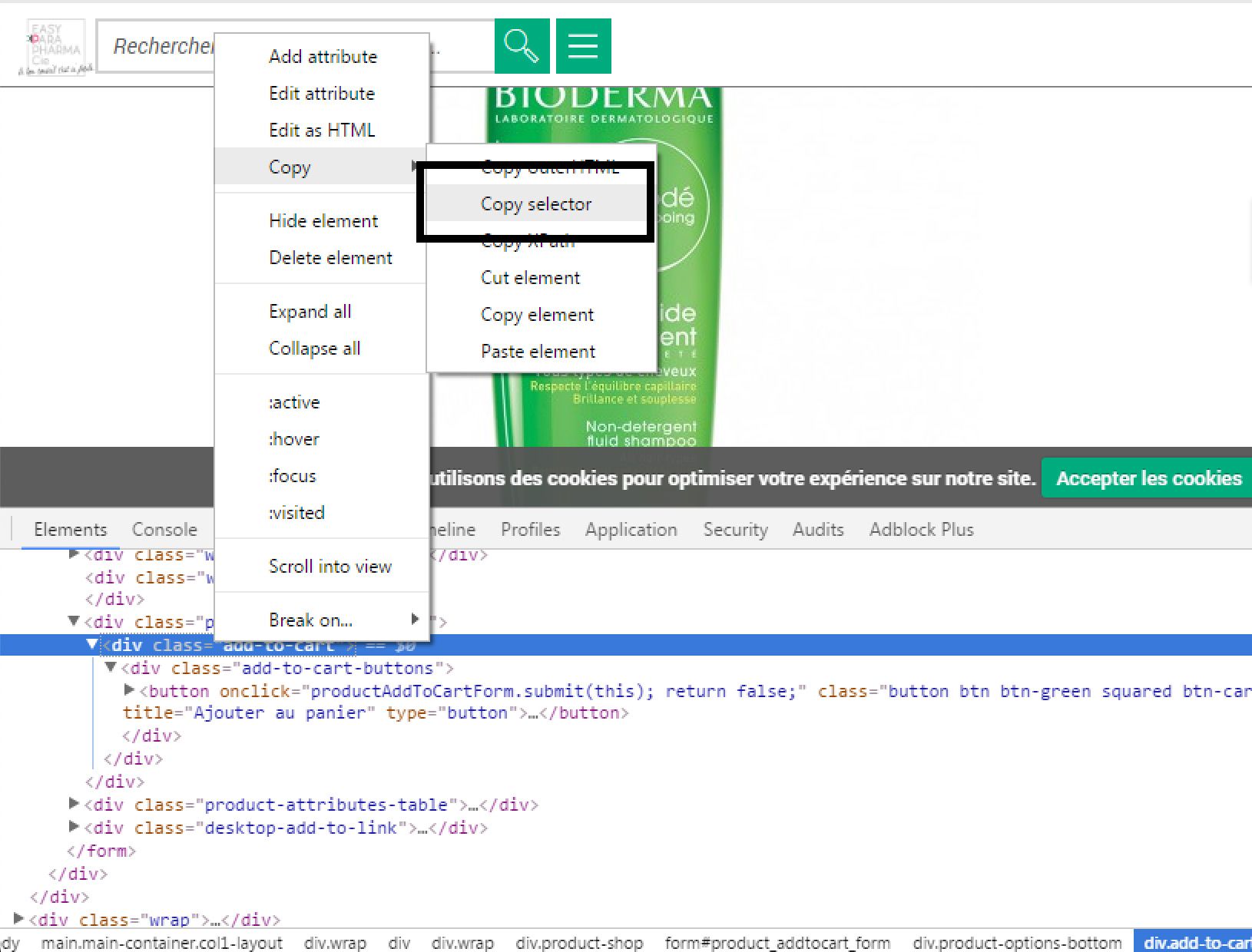
Voilà, nous avons à présent le chemin CSS du bouton au cœur de la page. Il ne reste plus qu’à configurer Screaming Frog de manière à ce qu’il puisse extraire le contenu de cet élément lors du crawl.
Rendez-vous dans Screaming Frog puis :
- Rendez-vous dans Configuration > Custom > Extraction
- Sélectionnez « CSS Path » dans la liste déroulante du premier élément
- Entrez un nom à votre extracteur (nous l’appellerons « stock »)
- Collez le chemin CSS que vous avez récupéré
- Sélectionnez le format de sortie souhaité (je vous laisse tester, nous utiliserons « texte » pour cet exemple, n’ayant pas besoin de plus
Voilà, votre crawll est prêt, vous pouvez à présent le lancer ! Entrez votre URL de départ et faites « start » en croisant les doigts bien fort : magie ! Une colonne « stock » a fait son apparition et elle vous remonte pour chaque page du site le contenu de la div du bouton d’ajout au panier :
- « Vide » si la div n’a pas été trouvée ou si elle était vide
- « Ajouter au panier » si le produit est disponible
- « Être prévenu […] » lorsque le produit n’est plus disponible
Il ne vous reste plus qu’à exporter votre rapport dans Excel, intégrer quelques filtres et passer à l’analyse des données !
Extraire vos descriptifs de catégories
En se basant sur la même méthode, vous pouvez extraire les textes descriptifs de vos pages catégorie : nous prenons ici l’exemple de www.deltanautic.fr, site e-commerce de vente de barques, moteurs et matériel nautique. Une fois le CCS Path récupéré depuis Chrome, nous utilisons le menu « Configuration > Custom > Extraction » afin de créer la colonne « cat_description » et nous lançons le crawl. Voici le résultat ci-dessous, une fois exporté dans Excel.
D’autres idées de données à extraire grâce au « custom extractor » de Screaming Frog
Que vous utilisiez le CSS Path ou le XPath, l’outil n’a globalement pour limite que votre imagination, le plus difficile étant souvent de faire le point sur les données dont on a vraiment besoin. Voici quelques exemples dont vous pouvez vous inspirer :
- Les noms de vos produit / catégories
- Les descriptifs de vos produits
- Le fil d’Ariane de chaque page
- Le nombre de likes Facebook si le chiffre apparaît sur la page
- Le nombre de commentaires sur chacun de vos articles de blog
- La note moyenne laissée par les internautes sur chaque produit
- Les microdata contenues sur les pages de votre site
D’autres idées ? N’hésitez pas à nous les soumettre en commentaires !
Guillaume
















